If you have stopped receiving emails from us, please check your SPAM folder.
Also, to help stop emails from getting mistagged as spam in the future,
be sure to add 'webmaster@my.icr.org' to your contact list!
Click here for more tips!
Also, to help stop emails from getting mistagged as spam in the future,
be sure to add 'webmaster@my.icr.org' to your contact list!
Click here for more tips!

Bees Master Complex Tasks Through Social Interaction
Bees are simply incredible.1,2 These little furry fliers challenge the very foundation of Darwinism in many diverse ways.
Bees have been delighting creationists for generations. These intelligent creatures can distinguish different humans from each other, as individuals, retaining memory of who is whom. Bees have remarkable math skills and communication abilities, including their use of “waggle dance” to inform other bees about where to find food.3
Consider also how
“Bees learn to fly the shortest possible route between flowers even if they...

Great Sand Dunes National Park and Preserve: Colossal Ice Age Remnants
The tallest sand dunes in North America are found in Great Sand Dunes National Park and Preserve, located on the eastern edge of the San Luis Valley in southern Colorado. The largest of the dunes reaches 700 feet above...
All the Lonely People
“I looked on my right hand, and beheld, but there was no man that would know me: refuge failed me; no man cared for my soul.” (Psalm 142:4)
This is one of the saddest verses in the Bible. To be all alone,...




The Latest

CREATION PODCAST
Ernst Haeckel: Evolutionary Huckster | The Creation Podcast:...
Ernst Haeckel, a German Zoologist, is famous for developing a series of images of embryos in development called Anthropogenie. These images,...
Bees Master Complex Tasks Through Social Interaction
Bees are simply incredible.1,2 These little furry fliers challenge the very foundation of Darwinism in many diverse ways.
Bees have been...
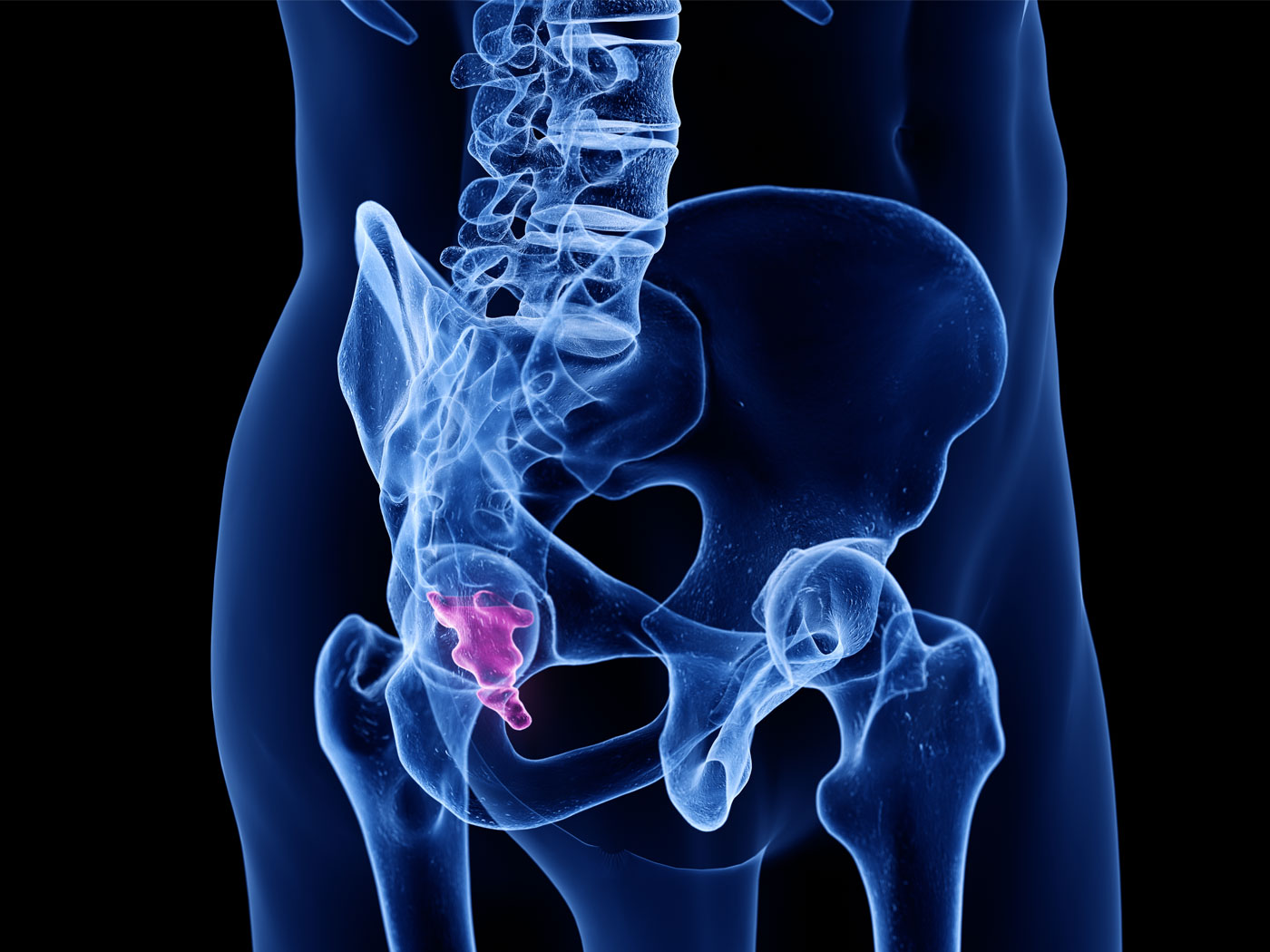
The Tail of Man’s Supposed Ancestors
Although it has been known for decades and despite insistence to the contrary from the evolutionary community, man—Homo sapiens—has never...

When Day Meets Night—A Total Success!
The skies cleared above North Texas on Monday, April 8, for a spectacular view of the 2024 Great American Solar Eclipse. Hundreds of guests joined...

The Sun and Moon—Designed for Eclipses
Before discovering thousands of planets in other solar systems, scientists tended to assume that other solar systems would be very similar to our own....

Let ICR Help You Prepare for the Great American Solar Eclipse!
On Monday, April 8th, the moon will move directly between the earth and the sun, resulting in a total solar eclipse visible in northern Mexico, much...

Total Eclipse on April 8th
“You alone are the LORD; You have made heaven, the heaven of heavens, with all their host, the earth and everything on it, the seas and all that...

CREATION PODCAST
Dismantling Evolution One Gear At A Time! | The Creation Podcast:...
The human body is a marvel of complexity and the more we learn about it, the more miraculous our existence becomes! Can evolution explain the...

April 2024 ICR Wallpaper
"He appointed the moon for seasons; The sun knows its going down." (Psalm 104:19 NKJV)
ICR April 2024 wallpaper is now available...
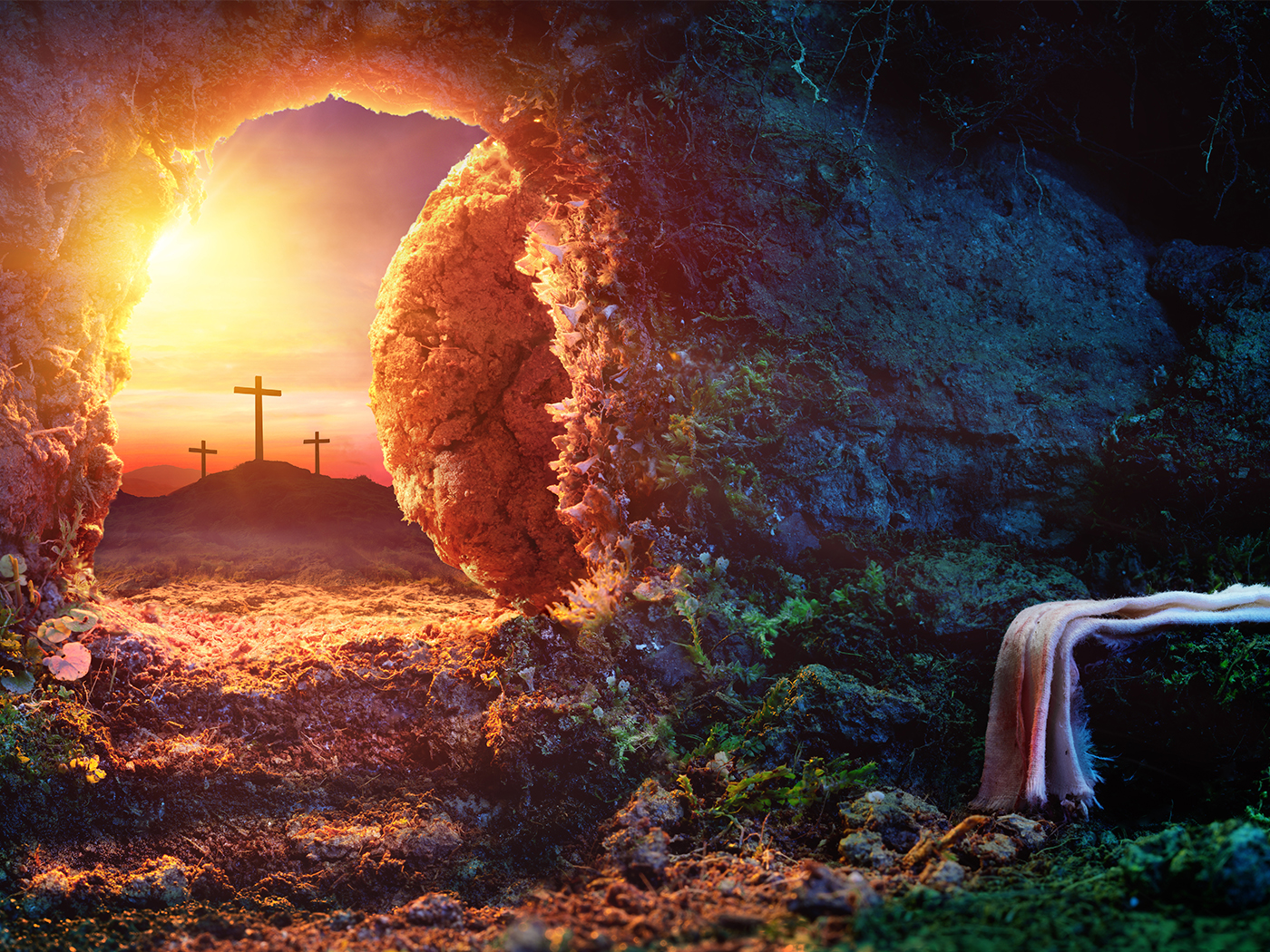
Creation's Easter Message
While many Christians still consider the creation doctrine a fringe issue, a proper understanding of the Christian message finds creation at its core...
Creation Kids

Featured Event

Kids on Mission
Video
Penguin Party: Surviving Extreme Cold
An Imaginary Theory #podcast #creationism
Take a Selfie with a T. rex!
Total Solar Eclipse Livestream and Watch Party
ICR Discovery Center
More in Video ⊳ICR Discovery Center